


一:数据库约束
数据库约束:为了保证数据库的安全性和完整性,数据库需要对数据进行一定的约束。具体约束类型有
NOT NULL:规定某列值不能为NULLUNIQUE:规定某列值必须唯一,不能有重复DEFAULT:规定某列再没有赋值时的默认值PRIMARY KEY:等于NOT NULL+UNIQUEFOREIGN KEY:参照完整性CHECK:规定某列中的值必须符号的条件
(1)NULL约束
create table student(
Sid int not null,
Sname varchar(20),
Smail varchar(20)
);
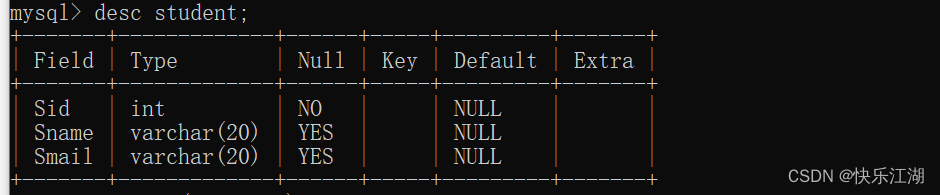
此时如果插入NULL就会报错
insert into student values(null, '张三', null);
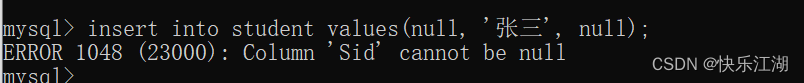
(2)UNIQUE约束
create table student(
Sid int not null,
Sgrade int unique,
Sname varchar(20),
Smail varchar(20)
);

此时如果插入时发现Sgrade重复就会报错
insert into student(Sid, Sname, Sgrade, Smail) values
(1, '张三', 72, 'test@qq.com'),
(2, '李四', 64, 'test2@qq.com'),
(3, '王五', 72, 'test3@qq.com');

(3)DEFAULT约束
create table student(
Sid int not null,
Sgrade int unique,
Sname varchar(20) default 'unknow',
Smail varchar(20)
);
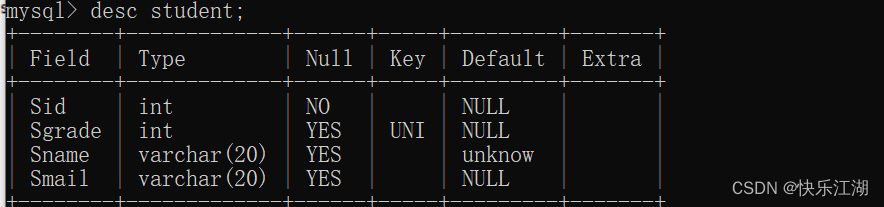
此时如果插入NULL并不会报错,而是会采用你所设定的那个默认值(需要按照指定列插入)
insert into student(Sid) values
(1),
(2);

(4)PRIMARY KEY约束
数据库设计时必须满足实体完整性,实体完整性可以用PRIMART KEY定义,它等于UNIQUE + NOT NULL
create table student(
Sid int primary key,
Sgrade int unique,
Sname varchar(20) default 'unknow',
Smail varchar(20)
);
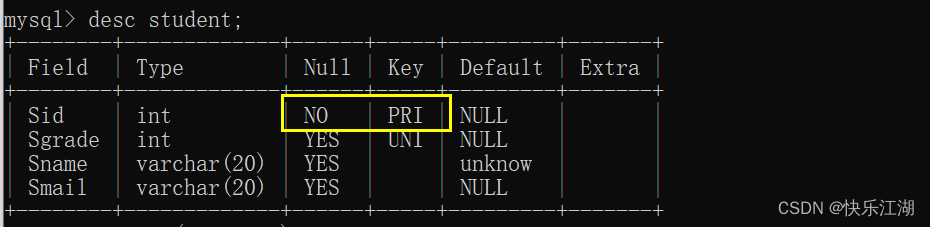
此时插入时如果主键重复或者为NULL则会报错
insert into student values
(1, 72, '张三', null),
(null, 73, '李四', null);

insert into student values
(1, 72, '张三', null),
(1, 77, '王五', null);

另外注意,对于整数类型的主键,常常会搭配自增长auto_increment来使用。在插入数据对应字段不给值时,使用最大值+1
create table student(
Sid int primary key auto_increment,
Sname varchar(20)
);
insert into student values
(null, '张三'),
(null, '李四'),
(null, '王五'),
(null, '赵六');

(5)FORETIGN KEY约束
数据库设计时还要满足参照完整性,参照完整性可以用FOREIGN KEY定义,同时用REFERENCES短语指明这些外码参照哪些表的主码
如下,创建班级表classes,有id和name两个字段;再创建学生表student,其中用classes_id表示学生所在班级,该classes_id取值必须参照classes中的id,所以使用外键约束
create table classes(
id int primary key auto_increment,
name varchar(20)
);
create table student(
id int primary key auto_increment,
sn int unique,
name varchar(20) default 'unknown',
classes_id int,
foreign key (classes_id) references classes(id)
);
此时classes称为被参照表,student称为参照表,一旦产生外键约束,用户在对参照表和被参照表操作时,Mysql将会对其进行违约检查,如果不符合参照完整性,就会触发对应的违约处理,具体行为见:
举个例子,被参照表是Student,参照表是sc,破坏参照完整性的行为及其违约处理如下表所示

对于参照表sc的行为
- 向
sc表(参照表)中插入一个元组,这是会被拒绝的。因为有可能你所插入的元组的Sno(外码)无法在Student表中找到,这就意味着在成绩表中插入了一个非本班同学的成绩,这显然是不合理的 - 修改
sc表(参照表)中的一个元组,这是会被拒绝的。因为有可能你会修改该元组的Sno(外码),这就可能导致Sno无法在Student表中好到 - 删除
sc表(参照表)中的一个元组,这是可行的。因为它无非就是一条成绩信息
对于被参照Student的行为
- 删除
Student表(被参照表)中的一个元组,这是会被拒绝(也有可能级联删除或设为NULL)的。因为删除一个元组后,该元组所对应的Sno(主码)将不复存在,这就有可能导致sc表(参照表)中某些元组的Sno(外码)在Student表中找不到 - 修改
Student表(被参照表)中的一个元组,这是会被拒绝(也有可能级联删除或设为NULL)的 。因为一旦修改了该元组的Sno属性,就会发生和上面一样的问题 - 向
Student表(被参照表)插入一个元组,这是可行的。因为它无非就是一个新同学嘛
(6)CHECK约束
数据库设计时也需要满足用户自定义完整性,用户自定义完整性使用CHECK定义,它可以对插入的数据进行控制,判断其是否满足插入条件
create table student(
Sname varchar(20),
Ssex varchar(1),
check(Ssex = '男' or Ssex = '女')
);
二:数据库设计
数据库设计(database design):数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构,并据此建立数据库及其应用系统,使之能够有效地存储和管理数据,满足各种用户的应用需求,包括信息管理要求和数据操作要求。数据库设计的目标是为用户和各种应用系统提供一个信息基础设施和高效的运行环境
- 信息管理要求:数据库中应该存储和管理哪些数据对象
- 数据操作要求:对数据对象需要进行哪些操作
数据库设计比较重要的话题就是逻辑结构设计,详细见
三:INSERT新增(进阶)
除了普通INSERT外,在新增数据时也可以把子查询结果作为数据插入
如下表
create table student(
Sname varchar(20),
Sage int,
Seamil varchar(20)
);
insert into student values
('张三', 18, '123@qq.com'),
('李四', 20, '321@qq.com'),
('王五', 24, '312@qq.com'),
('赵六', 19, '213@qq.com'),
('田七', 21, '231@qq.com');
create table test_user(
Uid int primary key auto_increment,
Uname varchar(20),
Uage int,
Usex varchar(1)
);
将student的查询结果插入到test_user当中去

四:SELECT查询(进阶)
注意: 此部分内容以下面表为例
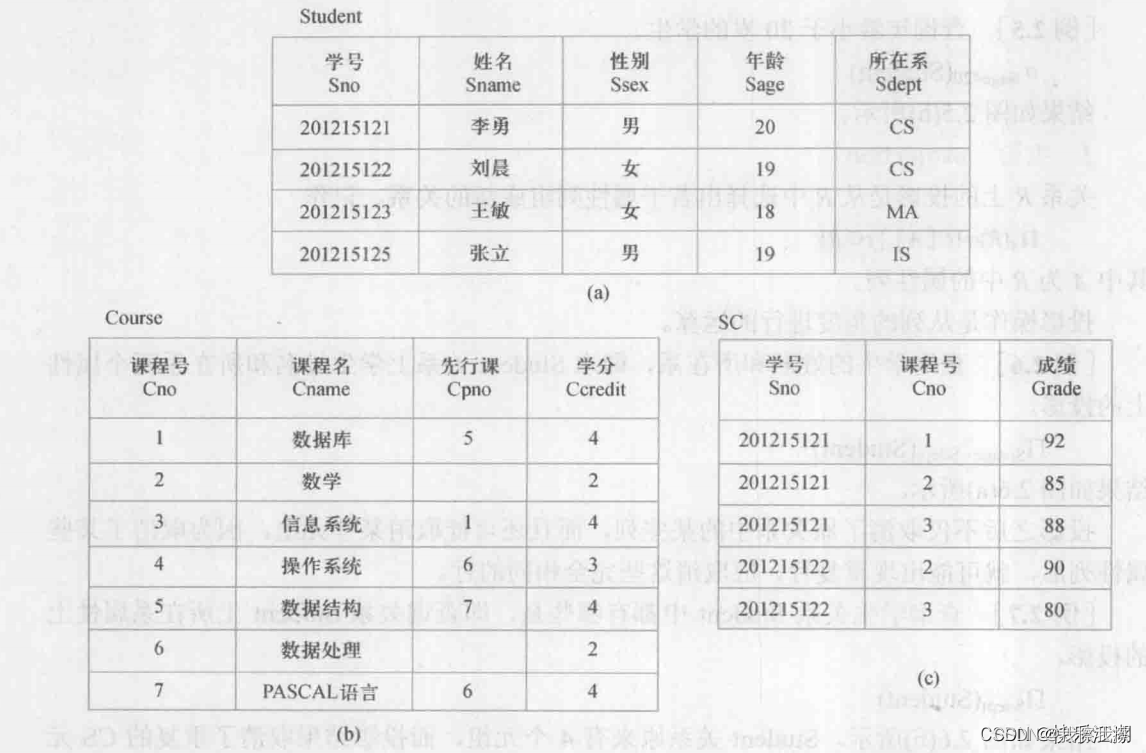
/*例3.5建立一个学生表*/
/*1、删除practice_db数据库(如果存在)*/
drop database if exists practice_db;
/*2、创建数据库practice_db数据库*/
create database practice_db charset utf8;
use practice_db; -- 选择jt_db数据库
/*3. 创建学生表Student(例3.5)*/
Create table Student(
Sno char(9) Primary key,/*列级完整性约束条件,Sno是主码*/
Sname char(20) unique,/*Sname取唯一值*/
Ssex char(2),
Sage smallint,
Sdept char(20)
);
/*4.插入学生信息*/
insert into Student values('201215121','李勇','男',20,'CS');
insert into Student values('201215122','刘晨','女',19,'CS');
insert into Student values('201215123','王敏','女',18,'MA');
insert into Student values('201215125','张立','男',19,'IS');
/*6.创建课程表Course(例3.6)*/
create table Course(
Cno char(4) primary key,
Cname char(40) Not NULL,
Cpno char(4),/*Cpno的含义是先行课*/
Ccredit smallint,
foreign key(Cpno) references Course(Cno) /*Cpno是外码,被参照表示Course,被参照列是Cno*/
);
/*6.插入课程信息*/
/*由于Course表以自身为外键约束,所以要先禁用外键约束插入数据,插入完成后再开启外键约束*/
SET FOREIGN_KEY_CHECKS=0; /*禁用外键约束*/
insert into Course values('1','数据库','5',4);
insert into Course values('2','数学','null',2);
insert into Course values('3','信息系统','1',4);
insert into Course values('4','操作系统','6',3);
insert into Course values('5','数据结构','7',4);
insert into Course values('6','数据处理','null',2);
insert into Course values('7','PASCAL语言','6',4);
SET FOREIGN_KEY_CHECKS=1; /*插入完成后开启外键约束*/
/*7.建立学生选课表SC(例3.7)*/
create table SC(
Sno char(9),
Cno char(4),
Grade smallint,
primary key (Sno,Cno), /*主码由两个属性构成,必须作为表级完整性进行定义*/
foreign key(Sno) references Student(Sno), /*表级完整性约束条件,Sno是外码,被参照表是Student*/
foreign key(Cno) references Course(Cno)/*表级完整性约束条件,Cno是外码,被参照表是Course*/
);
/*8.插入学生选课信息*/
insert into SC values('201215121','1',92);
insert into SC values('201215121','2',85);
insert into SC values('201215121','3',88);
insert into SC values('201215122','2',90);
insert into SC values('201215122','3',80);
(1)聚合查询
对于统计总数、计算平均值等操作可以借助聚合查询(聚集函数)来完成
例子:
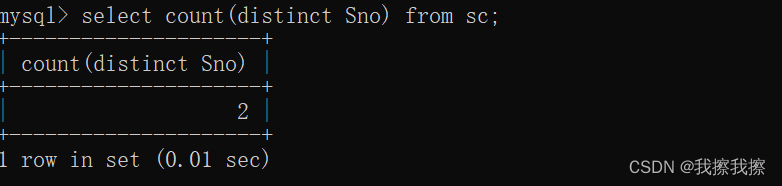
①count:查询选修了课程的有几个
count(*)会统计null值
select count(distinct Sno) from sc;
②:sum:统计学号为201215121这名同学选课的总成绩
null值不参与运算sum只能针对数字进行
select Sno, sum(Grade) as '总成绩' from sc where Sno like '201215121';

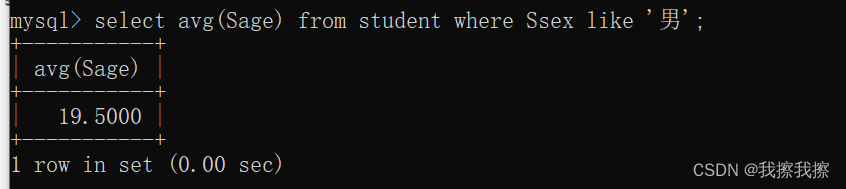
③:avg:统计student中男生的平均年龄
select avg(Sage) from student where Ssex like '男';
(2)GROUP BY和HAVING
GROUP BY:GROUP BY子句将查询结果按某一列或多列的值分组,值相等的分为一组
- 分组目的是为了细化聚集函数的作用对象:若未分组,聚集函数将会作用于整个查询结果;若分组,聚集函数将会作用于每一个组,也即每一个组都有一个函数值
- 需要注意:WHERE子句作用于整个表或视图,从中选择出满足条件的元组;HAVING短语作用于组,从中选择满足条件的组
相信读完之后大家可能还是有点迷糊,举个例子。比如我要查询“各个课程对应的选课人数”,如果没有GROUP BY子句
SELECT Cno,Count(Sno)
FROM sc;
由于它会作用于整个查询结果,所以直接统计出了记录的条数
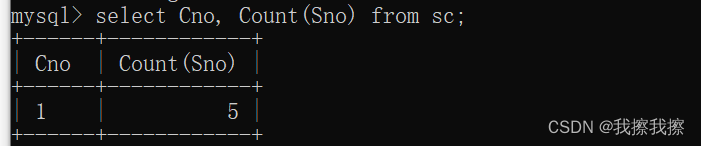
如果加入GROUP BY子句,按照课程号分组,那么GROUP BY会按照Cno进行分组,相同的为一组,然后在每组内统计Sno
SELECT Cno,Count(Sno)
FROM sc
GROUP BY Cno;
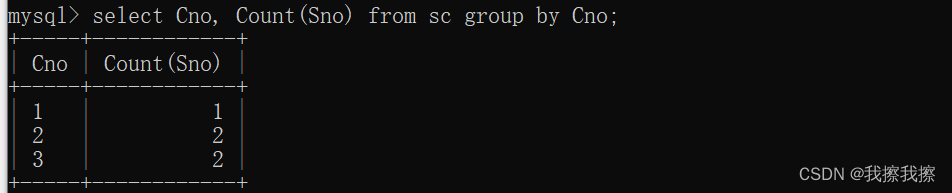
而如果我只想显示那些选课人数大于1以上的课程号呢,那么就可以使用HAVING短语,在组内进行筛选
SELECT Cno,Count(Sno)
FROM sc
GROUP BY Cno
HAVING Count(Sno) > 1;

例子:
查询平均成绩大于等于80分的学生学号和平均成绩
SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno
HAVING AVG(Grade) >= 80;

(3)多表查询
- 注意:多表查询涉及关系运算,详见(数据库系统概论|王珊)第二章关系数据库-第四节:关系代数
A:等值连接和非等值连接
语法:在WHERE子句中写入连接条件(又叫做连接每谓词),其格式为

其中比较运算符有:=、>、<、>=、<=、!=
- 当运算符为
=时称之为等值连接 - 当运算符不为
=时称之为非等值连接
例子:
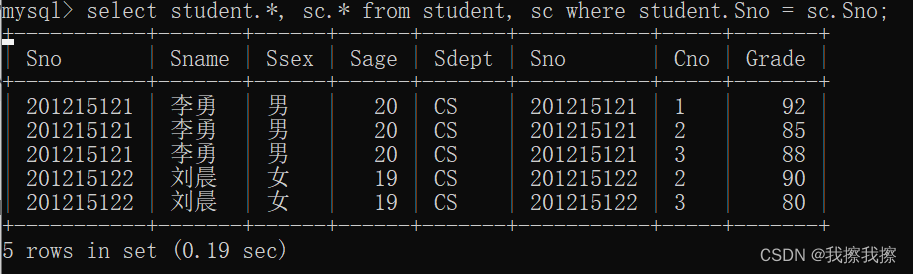
①:查询每个学生及其选修课程的情况
SELECT student.*,sc.*
FROM student,sc
WHERE student.Sno=sc.Sno;
②:查询选修2号课程且成绩在80分以上的所有学生的学号和姓名
SELECT Student.Sno,Sname
FROM student,sc
WHERE student.Sno=sc.Sno AND //连接条件
Cno='2' AND Grade > 80; //其他限定条件

B:自身连接
语法:所谓自身连接就是指一个表与自己连接
例子:
查询每一门课的先修课的先修课
- 在
Course表中有的只是每门课的直接先修课,要想得到先修课的先修课,那么就必须先找到一门课的先修课,然后再按此先修课的课程号查找它的先修课
因此,为Course表取两个别名,分别为ONE和TWO
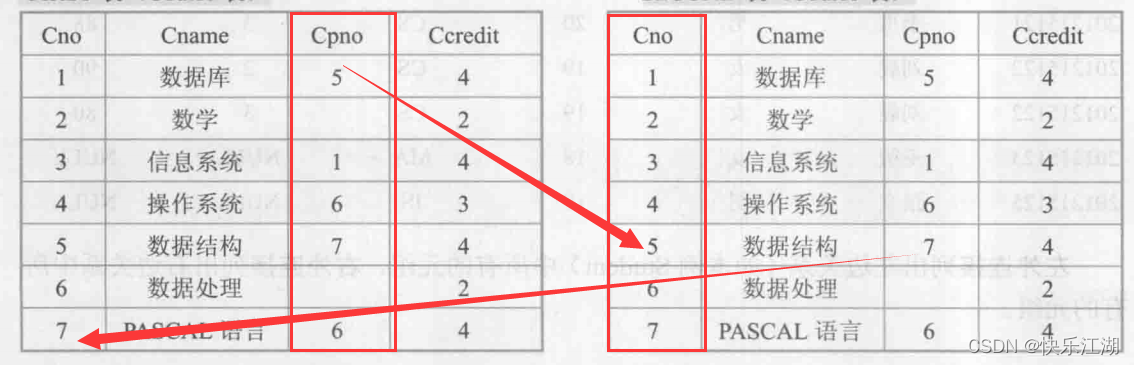
SELECT ONE.Cno,TWO.Cpno
FROM Course ONE,Course TWO
WHERE ONE.Cpno=TWO.Cno;

C:连接JOIN
语法:SQL JOIN用于把来自两个或多个表的行结合起来,其格式如下
SELECT column_name(s)
FROM TABLE1//左表
<某某 JOIN>TABLE2//右表
ON TABLE1.column_name=TABLE2.column_name
有如下几类
-
INNER JOIN(JOIN):关键字在表中存在至少一个匹配时返回行
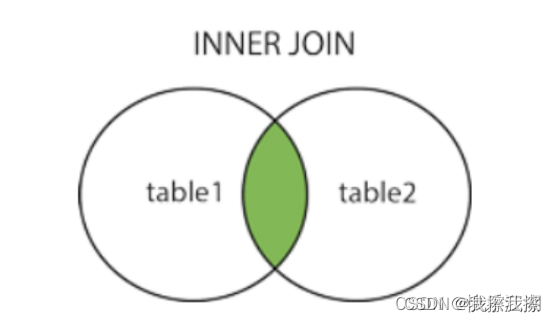
-
LEFT JOIN(LEFT OUTER JOIN):以左表为标准,若右表中无匹配,则填NULL
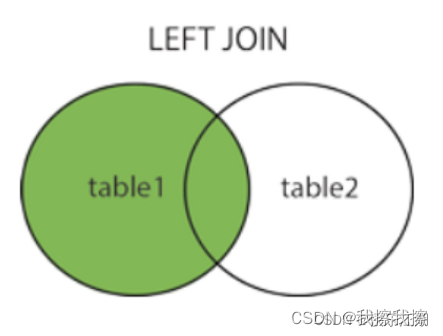
-
RIGHT JOIN(RIGHT OUTER JOIN):以右表为标准,若左表中无匹配,则填NULL
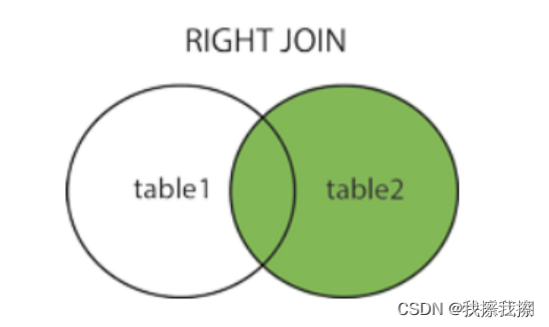
-
FULL JOIN(FULL OUTER JOIN):本质就是结合了LEFT JOIN和RIGHT JOIN
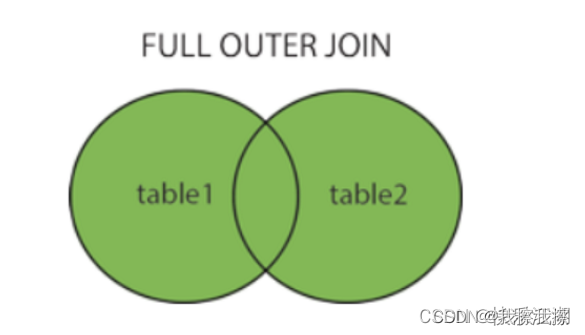
例子:
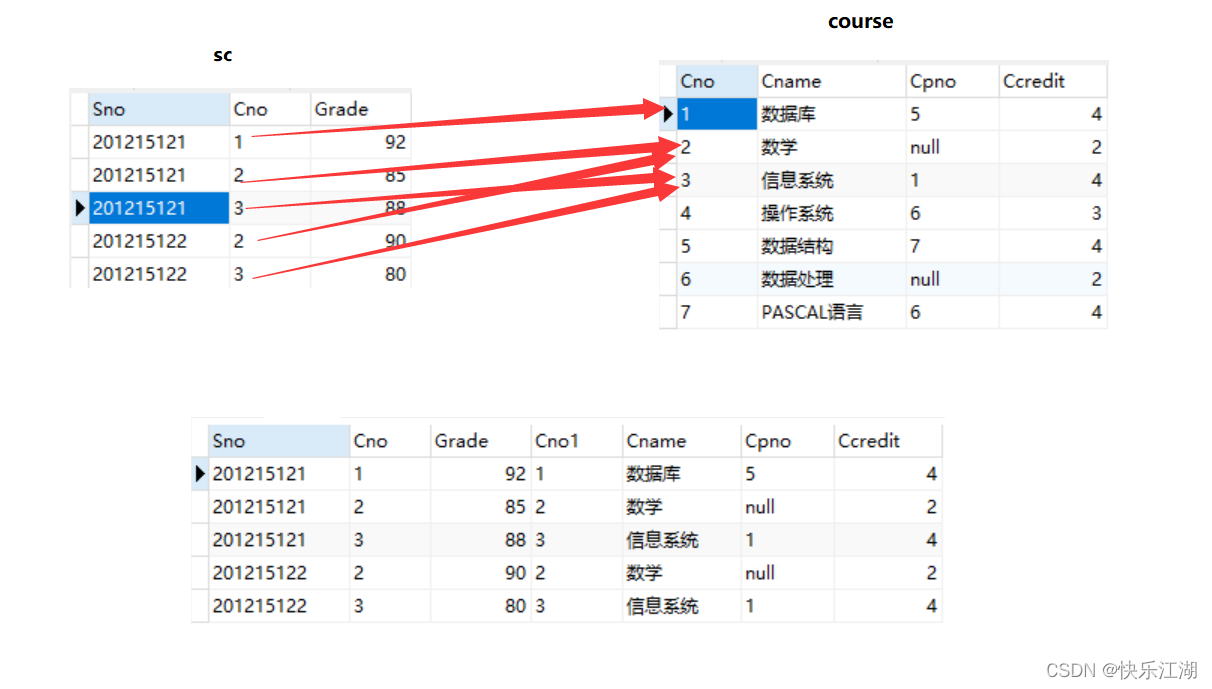
①:以sc和course的Cno作为比对标准,将相同连接在一起
SELECT Sno,sc.Cno,Grade,course.Cno,Cname,Cpno,Ccredit
FROM sc INNER JOIN course ON(sc.Cno=course.Cno);

②:
SELECT Sno,sc.Cno,Grade,course.Cno,Cname,Cpno,Ccredit
FROM sc LEFT JOIN course ON(sc.Cno=course.Cno);

③:
SELECT Sno,sc.Cno,Grade,course.Cno,Cname,Cpno,Ccredit
FROM sc RIGHT JOIN course ON(sc.Cno=course.Cno);
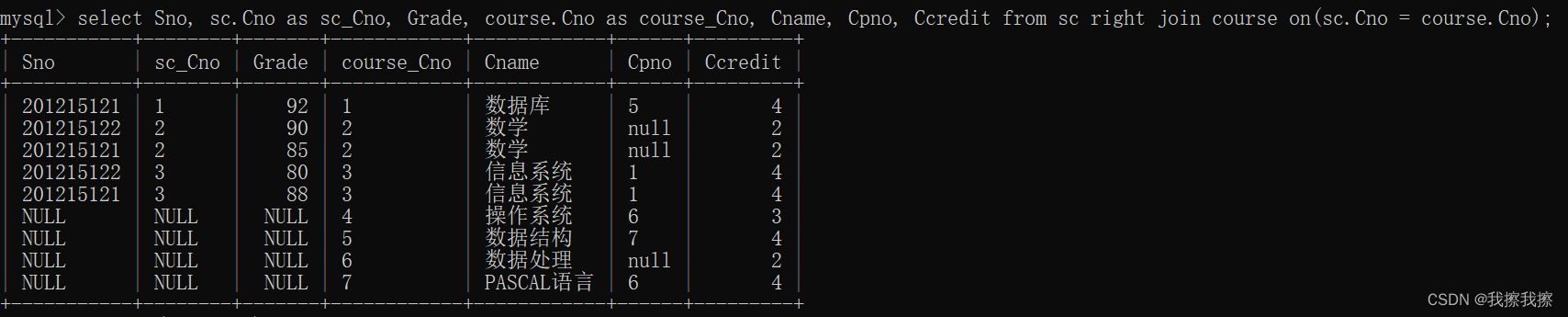
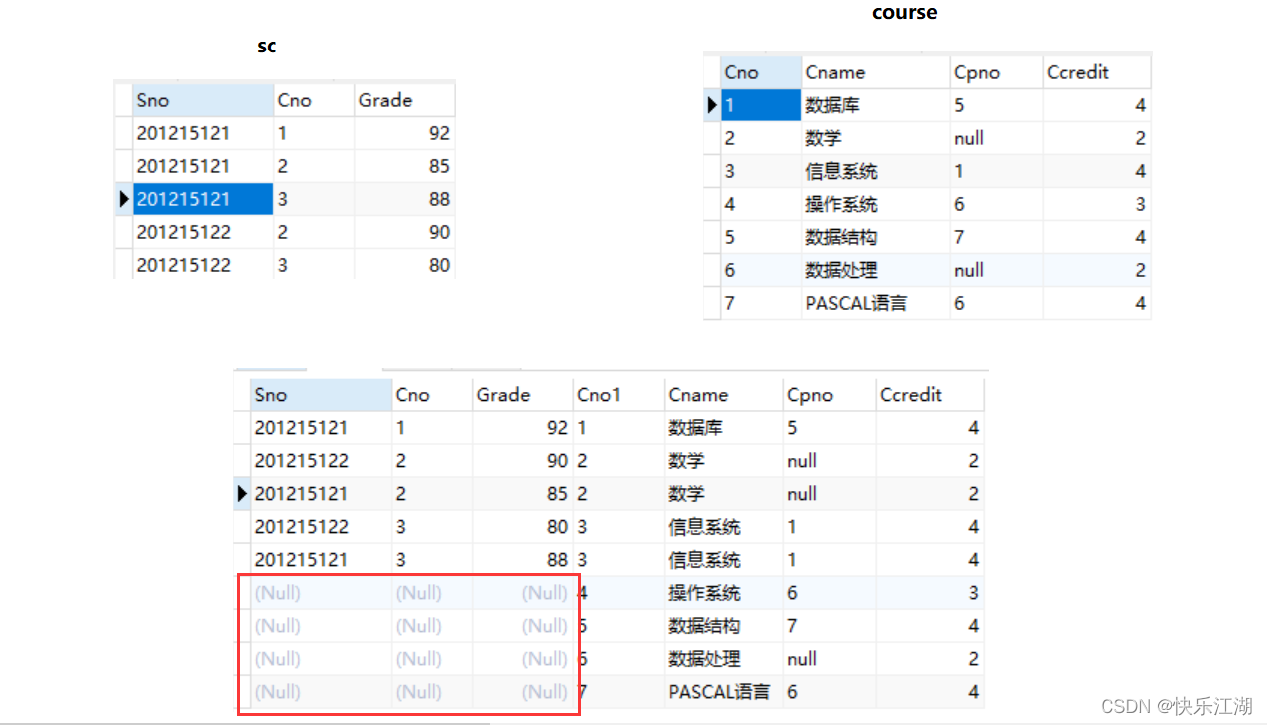
④:
SELECT Sno,sc.Cno,Grade,course.Cno,Cname,Cpno,Ccredit
FROM sc FULL JOIN course ON(sc.Cno=course.Cno);
(4)子查询
子查询在实际开发中使用频次并不是那么高,因为它不容易理解,详细可了解
评论区